
Infrastructure as Code Explained: Stop Clicking in the Console
Apr 12, 2026
It was 3 AM on a Tuesday. That’s exactly when I realized I’d been solving the exact same problem for the third time that month.
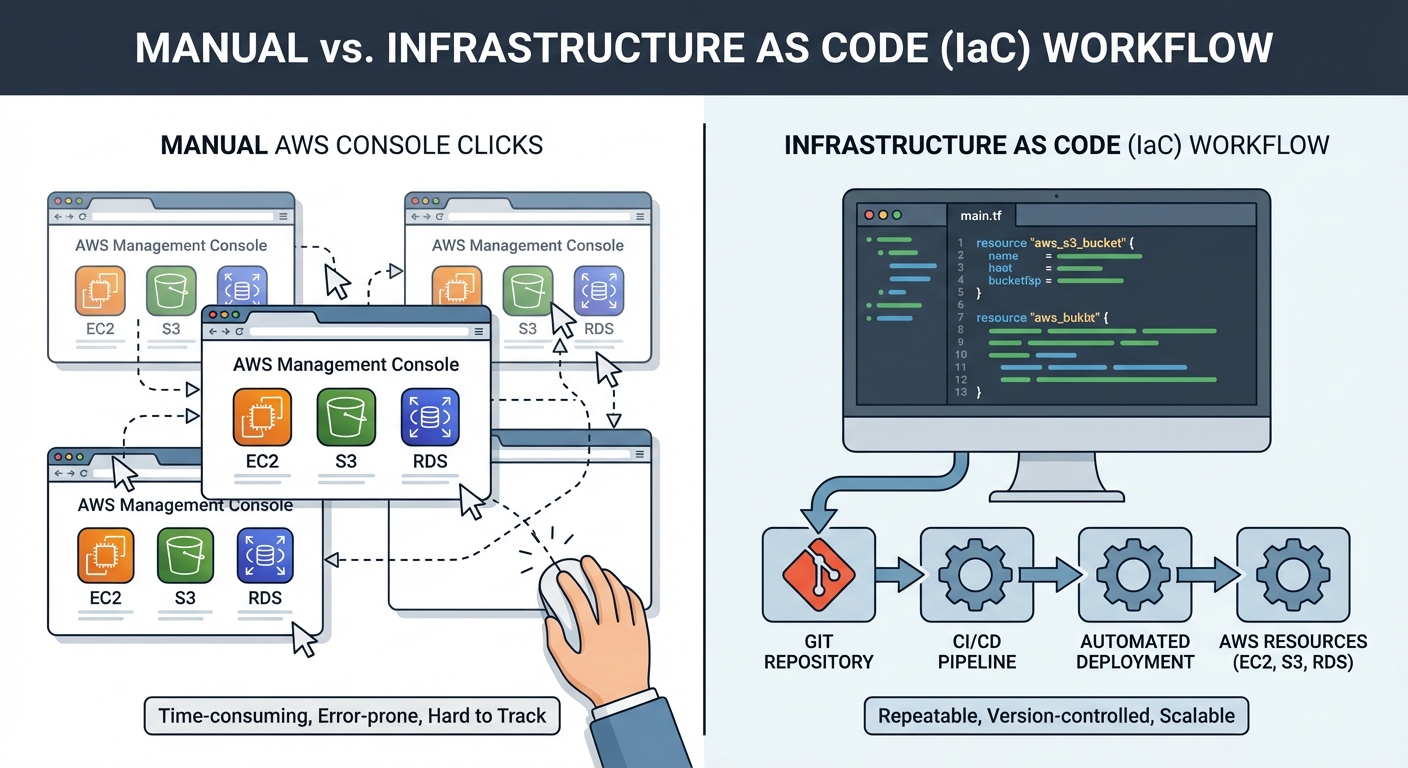
Our team at a mid-sized fintech startup had just spun up a new staging environment for a client demo. And when I say spun up, I mean it took us two full days of absolute grinding. We spent those forty-eight hours SSHing into servers, running the exact same bash scripts over and over, and manually configuring load balancers through the AWS console. We set up security groups, tweaked obscure database parameters—you name it, we clicked it. When the demo ended, we tore it all down. Then, three weeks later, the client wanted to see something else, so we needed the environment again. So we did it all over. We literally just did the whole two-day process all over again. This time, though, someone forgot to enable a single monitoring hook. One hook. We spent an entire afternoon debugging something that completely shouldn’t have been an issue in the first place.
That’s when it finally hit me. We were treating infrastructure like some magical, one-off thing that only lived in one person’s head—like a fragile sandcastle that washed away with the next wave. Nobody documented the exact steps. The configuration existed nowhere except in the actual running systems. If something broke, we’d SSH in, poke around, and fix it manually. That meant the next person who looked at the server wouldn’t know what we’d changed or why we’d changed it.
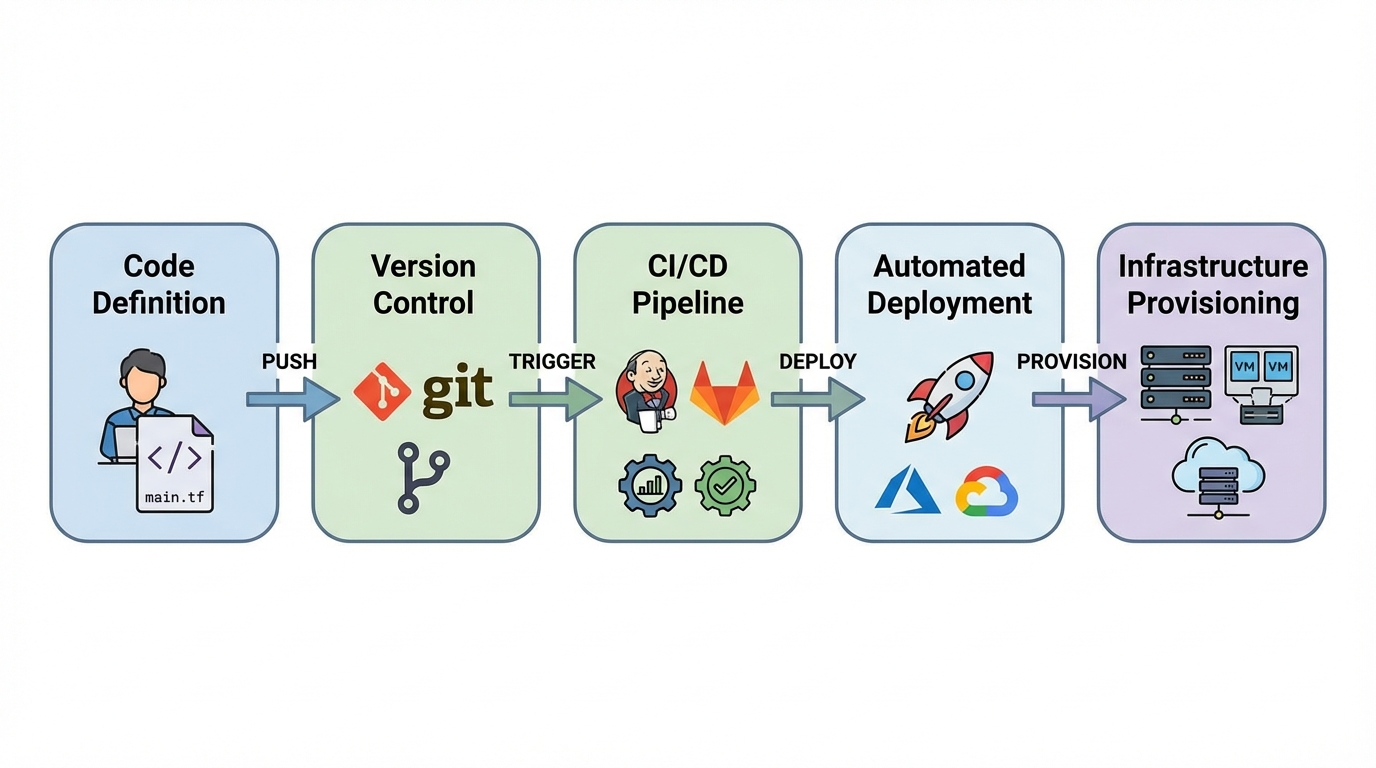
Infrastructure as Code solved this for me, but not in the way I expected.
IaC isn’t really about the code, honestly. It’s about treating your infrastructure like something that deserves version control, testing, and documentation just as much as your frontend application does. When I started writing Terraform files, I wasn’t just automating deployment. I was creating a single source of truth that actually made sense. Every server, database, firewall rule—everything was defined in plain text that I could actually read months later. It lived right there in Git alongside our application code.
Looking back, I probably should have started with this at my first DevOps role. I spent years doing it the hard way. Manual configurations, tribal knowledge, late-night SSH sessions trying to remember what the hell I’d changed last time… In one particularly memorable disaster, I accidentally deleted a kernel file on a RHEL system and had to rebuild the entire machine from scratch. (Don’t ask how many times that happened. More than once, let’s say. Actually, it was exactly three times, but who’s counting?)
The real breakthrough came when I finally integrated IaC into our CI/CD pipeline with Jenkins. No more clicking around the AWS console like a lost tourist hoping not to break production. A pull request would trigger a terraform plan, which showed exactly what changes were coming. After review, it would automatically deploy. For the first time ever, our infrastructure changes had actual audit trails. We could see exactly who changed what, when they did it, and why. It felt like magic, honestly.
I know this is slightly off-topic—and I promise I’ll get back to the main point in a second—but I used to think Flux CD was different than Argo CD
🚀 Want the full picture?
I put together RHCSA Bootcamp (RHEL 10) - Arabic for people who want the whole journey, not scattered tutorials. Step-by-step lessons, real labs, and the details I wish someone had taught me early on.
